HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
Abstract
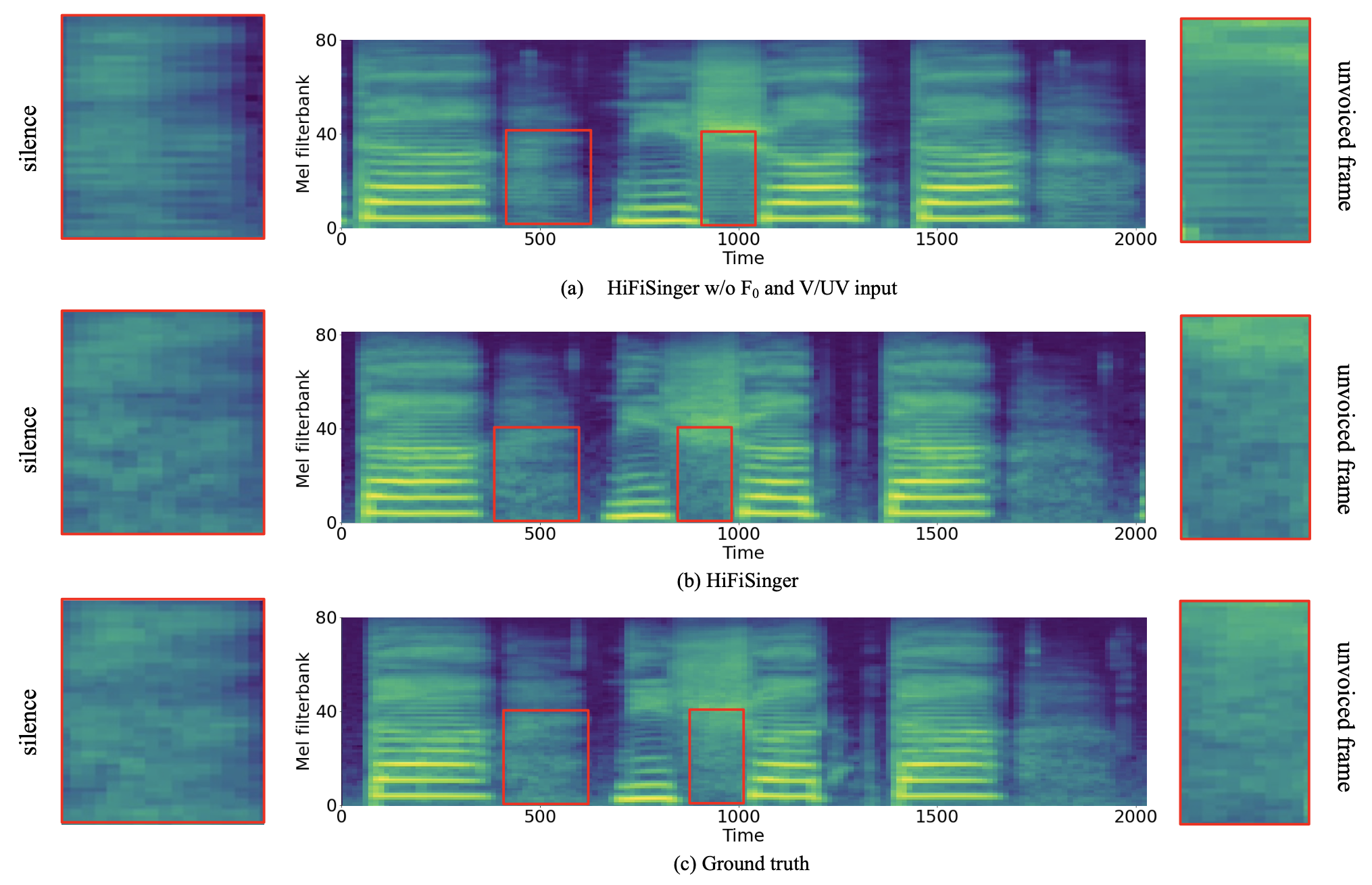
High-fidelity singing voices usually require higher sampling rate (e.g., 48kHz, compared with 16kHz or 24kHz in speaking voices) with large range of frequency to convey rich expression and emotion. However, higher sampling rate results in wider frequency band and longer waveform sequence with more fine-grained details and presents challenges for singing modeling in both frequency and time domains in singing voice synthesis (SVS). In this paper, we develop HiFiSinger, an SVS system towards high-fidelity singing voice using 48kHz sampling rate. HiFiSinger consists of a FastSpeech based neural acoustic model and a Parallel WaveGAN based neural vocoder to ensure fast training and inference and also high voice quality. To tackle the difficulty of singing modeling caused by high sampling rate (wider frequency band and longer waveform), we introduce multi-scale adversarial training in both the acoustic model and vocoder to improve singing modeling. Specifically, 1) To handle the larger range of frequencies caused by higher sampling rate (e.g., 48kHz vs. 24kHz), we introduce a novel sub-frequency GAN (SF-GAN) on mel-spectrogram generation, which splits the full 80-dimensional mel-frequency into multiple sub-bands (e.g. low, middle and high frequency bands) and models each sub-band with a separate discriminator. 2) To model longer waveform sequences caused by higher sampling rate, we introduce a multi-length GAN (ML-GAN) for waveform generation to model different lengths of waveform sequences with separate discriminators. 3) We also introduce several additional designs in HiFiSinger that are crucial for high-fidelity voices, such as adding F0 (pitch) and V/UV (voiced/unvoiced flag) as acoustic features, choosing an appropriate window and hop size for mel-spectrogram, and increasing the receptive field in vocoder for long vowel modeling in singing voices. Experiment results show that HiFiSinger synthesizes high-fidelity singing voices with much higher quality: 0.32/0.44 MOS gain over 48kHz/24kHz baseline and 0.83 MOS gain over previous SVS systems.
48kHz sampling rate is used unless otherwise stated.
Audio Quality
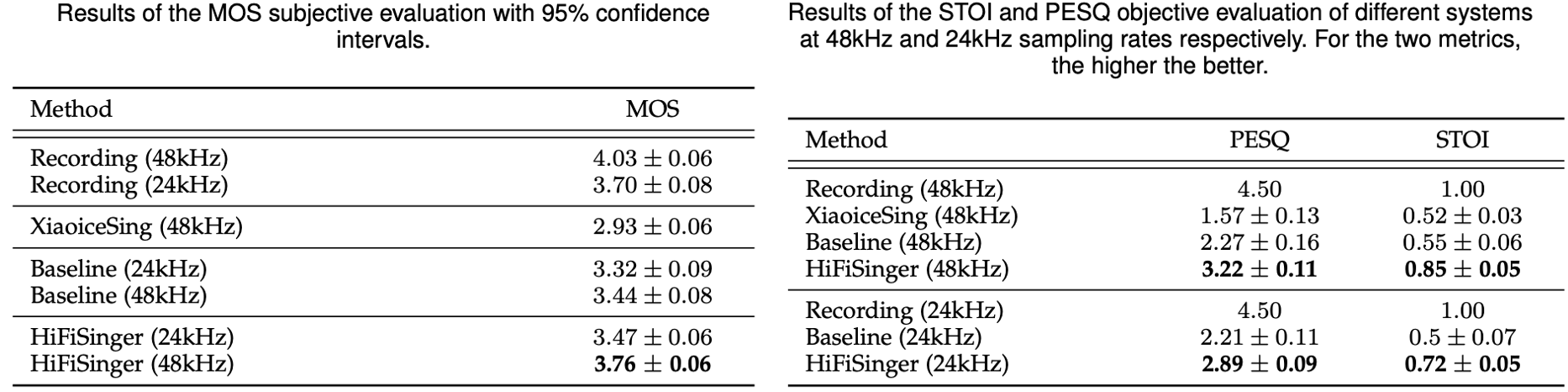
Recording , the original singing recordings. Recording (24kHz) , the original singing recordings downsampled to 24kHz. XiaoiceSing (48kHz) , a previous SVS system that also adopts high sampling rate of 48kHz but leverages WORLD vocoder. Baseline (24kHz) , a baseline SVS system that uses the basic model backbone of HiFiSinger but without any of our improvements in HiFiSinger, and only uses 24kHz sampling rate. Baseline (48kHz) , the same baseline system as Baseline (24kHz) but uses 48kHz sampling rate for training and inference. HiFiSinger (24kHz) , our proposed HiFiSinger system but uses 24kHz sampling rate. HiFiSinger (48kHz) , our final HiFiSinger system with 48kHz sampling rate.